Fast Inverse Distance Weighting (IDW) Interpolation with Rcpp
A common task in the field of geostatistics is interpolation. According to the first law of Geography, “Everything is related to everything else. But near things are more related than distant things.” (Tobler 1970). We can make use of this to interpolate values over a spatial region from a finite set of observations. There are already a number of great sources that describe geospatial interpolation methods (GISGeography 2016; Hartmann, Krois, and Waske 2018; Dunnington 2019; Wilke 2020). So in this post I don’t want to explain these methods again, but instead give a practical example on how to implement Inverse Distance Weighting (IDW) in C++ with Rcpp. I will explain the Rcpp code step by step, the finished result is available in the GVI R package on GitHub.
GISGeography (2016) provides an excellent explanation of the maths behind IDW. In short, the interpolated value of any location is based on the values of known locations, assuming closer values are more related than further values.
\[ z = \frac{\sum_{i}^{n}\frac{z_i}{{d_i}^\beta}}{\sum_{i}^{n}\frac{1}{{d_i}^\beta}} \]
where \(z\) is the value to be interpolated, \(n\) the number of surrounding known locations, and \(z_i\) and \(d_i\) their corresponding value and distance, respectively. \(\beta\) describes the distance power, that determines the degree to which nearer points are preferred over more distant points.
Below is a small example visualized using the rayshader R package:
| Distance | Value |
|---|---|
| 300 | 12 |
| 800 | 8 |
| 850 | 10 |
| 1300 | 9 |

Using the equation we can manually calculate the value \(z\) for the point in the middle with \(\beta = 2\) as:
\(z = (\frac{12}{300^2} + \frac{8}{800^2} + \frac{10}{850^2} + \frac{9}{1300^2}) / (\frac{1}{300^2} + \frac{1}{800^2} + \frac{1}{850^2} + \frac{1}{1300^2})\approx 11.3\)
Computing IDW with Rcpp
Data
First of all we need some data to interpolate. For that we will follow along the example of the FU-Berlin (Hartmann, Krois, and Waske 2018) and use weather station data provided by the Deutscher Wetterdienst (DWD) (German Weather Service).
library(dplyr)
library(sf)
# Retrieve Federal States by the the getData() function from the raster package
east_germany <- c('Sachsen', 'Sachsen-Anhalt', 'Berlin',
'Mecklenburg-Vorpommern','Brandenburg', 'Thüringen')
aoi <- raster::getData(country = "Germany", level = 1) %>%
st_as_sf() %>%
filter(NAME_1 %in% east_germany) %>%
st_transform(3035) %>%
st_union()
# Download DWD data
dwd <- read.csv2("https://userpage.fu-berlin.de/soga/300/30100_data_sets/DWD.csv",
stringsAsFactors = FALSE) %>%
as_tibble() %>%
select('LAT','LON', "MEAN.ANNUAL.RAINFALL", "ALTITUDE") %>%
rename(rain = "MEAN.ANNUAL.RAINFALL") %>%
na.omit()
# Convert to SF and transform to ETRS89/LAEA Europe
dwd.sf <- st_as_sf(dwd, coords = c("LON","LAT"), crs = 4326) %>%
st_transform(3035) %>%
st_intersection(aoi)
For the Rcpp algorithm, we need to convert the shapefile to a raster first and extract the raster values.
library(raster)
dwd.rast <- raster(xmn = st_bbox(dwd.sf)[1],
xmx = st_bbox(dwd.sf)[3],
ymn = st_bbox(dwd.sf)[2],
ymx = st_bbox(dwd.sf)[4],
crs = st_crs(dwd.sf)$proj4string,
resolution = 10000) %>%
rasterize(dwd.sf, ., "rain", background = NA)
dwd.rast_values <- getValues(dwd.rast)Rcpp code
We use the S4 structure of raster objects to read basic raster information (e.g. resolution, nrow, …) from the input raster. For that I’ll include the RasterInfo structure that you can find here. The Rcpp implementation of the IDW algorithm has the following general structure:
#include <Rcpp.h>
#include "rsinfo.h"
using namespace Rcpp;
// [[Rcpp::export]]
NumericVector IDW_Rcpp(S4 &rast, const NumericVector &x,
const int n, const double b, const double radius)
{
// Basic raster information
RasterInfo rast_info(rast);
// Convert radius to pixel
const int r_pxl = (int)(radius/rast_info.res);
// Output
NumericVector out(x.size(), NA_REAL);
// Main loop: Loop over all values of the raster x
for(int j = 0; j < x.size(); j++){
// 1. Convert j to row/col and X/Y coordinates
// 2. Calculate distance to all cells and store their values
// 3. Sort by distance and select top n
// 4. Compute IDW
}
return out;
}Below I will explain all four sections in detail, you can find the final source code on GitHub. Also, if you would like to support multithreading, it is really simple using OpenMP. We’ll come back to that later.
1. Convert j to row/col and X/Y coordinates
We can use simple math to obtain the row/col and X/Y coordinates from the current cell \(j\).
// row col from cell
const int row_j = j / rast_info.ncol;
const int col_j = j - (row_j * rast_info.ncol);
// XY from cell
const double y_j = rast_info.ymax - (row_j + 0.5) * rast_info.res;
const double x_j = rast_info.xmin + (col_j + 0.5) * rast_info.res;2. Calculate distance to all cells and store their values
To calculate the distance to the current cell \(j\) and the corresponding value we need to iterate over all cells that are within the radius. For that we take the row (or column) $row_j$ and loop over all rows (or columns) \(row_i\), where \(row_j-radius <= row_i <= row_j+radius\).
Again, the cell \(i\) and X/Y coordinates can be calculated using simple math. The distance from \(j\) to \(i\) is calculated using simple euclidean distance. Of course one could take the earths curvature into account, but let’s keep it simple for now. Finally, the distance and value of cell \(i\) will be stored. Note, that the cells \(i\) and \(j\) can be identical. In this case \(d\) would be \(0\) and result in a math error due to division by zero. Therefore, we simply store a fraction of the raster resolution in this case. One could also store a very small number or even the true value of \(i\). However, while testing different values, this led to very pointy interpolation maps.
// Distance (d) and value (z) vector
std::vector<double> d;
std::vector<double> z;
// Iterate over all cells that are within the radius
for(int row_i = row_j-r_pxl; row_i <= row_j+r_pxl; row_i++){
if(row_i > 0 && row_i < rast_info.nrow){
for(int col_i = col_j-r_pxl; col_i <= col_j+r_pxl; col_i++){
if(col_i > 0 && col_i < rast_info.ncol){
// Cell from row/col
const int i = row_i * rast_info.ncol + col_i;
const double i_value = x[i];
if(!NumericVector::is_na(i_value)) {
// XY from cell
const double y_i = rast_info.ymax - (row_i + 0.5) * rast_info.res;
const double x_i = rast_info.xmin + (col_i + 0.5) * rast_info.res;
// Distance
const double dist = sqrt((x_j-x_i)*(x_j-x_i) + (y_j-y_i)*(y_j-y_i));
// Save distance and value
if(i == j){
d.push_back(rast_info.res/4);
z.push_back(i_value);
} else if(dist <= radius) {
d.push_back(dist);
z.push_back(i_value);
}
}
}
}
}
}3. Sort by distance and select top n
To efficiently select only the top \(n\) values I have created a little helper function findBestIndices. It takes a distance vector d and the number of values N that should be returned, and returns N indices of d sorted by distance. So for example if we have a vector d = c(4,1,6,0) and N = 3, the function returns c(3, 1, 0) (C++ starts indexing from 0).
std::vector<int> findBestIndices(std::vector<double> &d, const int &N)
{
std::vector<int> indices(d.size());
std::iota(indices.begin(), indices.end(), 0); // fill with 0,1,2,...
std::partial_sort(indices.begin(), indices.begin()+N, indices.end(),
[&d](int i,int j) {return d[i]<d[j];});
return std::vector<int>(indices.begin(), indices.begin()+N);
}Now we can apply this function in our main loop:
// 3. Sort by distance and select top n
int nn = (d.size() < n) ? d.size() : n;
// Index of n shortest distances
std::vector<int> idx = findBestIndices(d, nn);
// And select value (z) and distance (d) in that order
std::vector<double> z_top_n;
std::vector<double> d_top_n;
for(auto t=idx.begin(); t!=idx.end(); ++t){
z_top_n.push_back(z[*t]);
d_top_n.push_back(d[*t]);
}4. Compute IDW
Finally, we have everything to interpolate the value for cell \(j\). Again, I’ve created a small helper function calc_idw that applies the equation from the beginning of this post.
double calc_idw(std::vector<double> &d, std::vector<double> &v, const double b){
double numerator = 0.0;
double denominator = 0.0;
// Sum from i to n
for(std::size_t i = 0; i < d.size(); i++){
numerator += v[i] / pow(d[i], b);
denominator += 1 / pow(d[i], b);
}
return numerator/denominator;
}And include it into the main loop:
// Compute IDW
out[j] = calc_idw(d_top_n, z_top_n, b);Comparison with gstat
The gstat R package provides a large set of functions useful for geostatistical modelling, prediction and simulation. I followed the instruction provided by the FU Berlin (Hartmann, Krois, and Waske 2018) and compared the results and computation time to the Rcpp method. Conveniently they have also conducted a cross validation to select the parameters \(n = 43\) and \(\beta = 1.5\) to reduce RMSE.
I have packed all steps for the two approaches into the helper functions dwd_rcpp and dwd_gstat, you can view them here.
Let’s look at the visual comparison first.
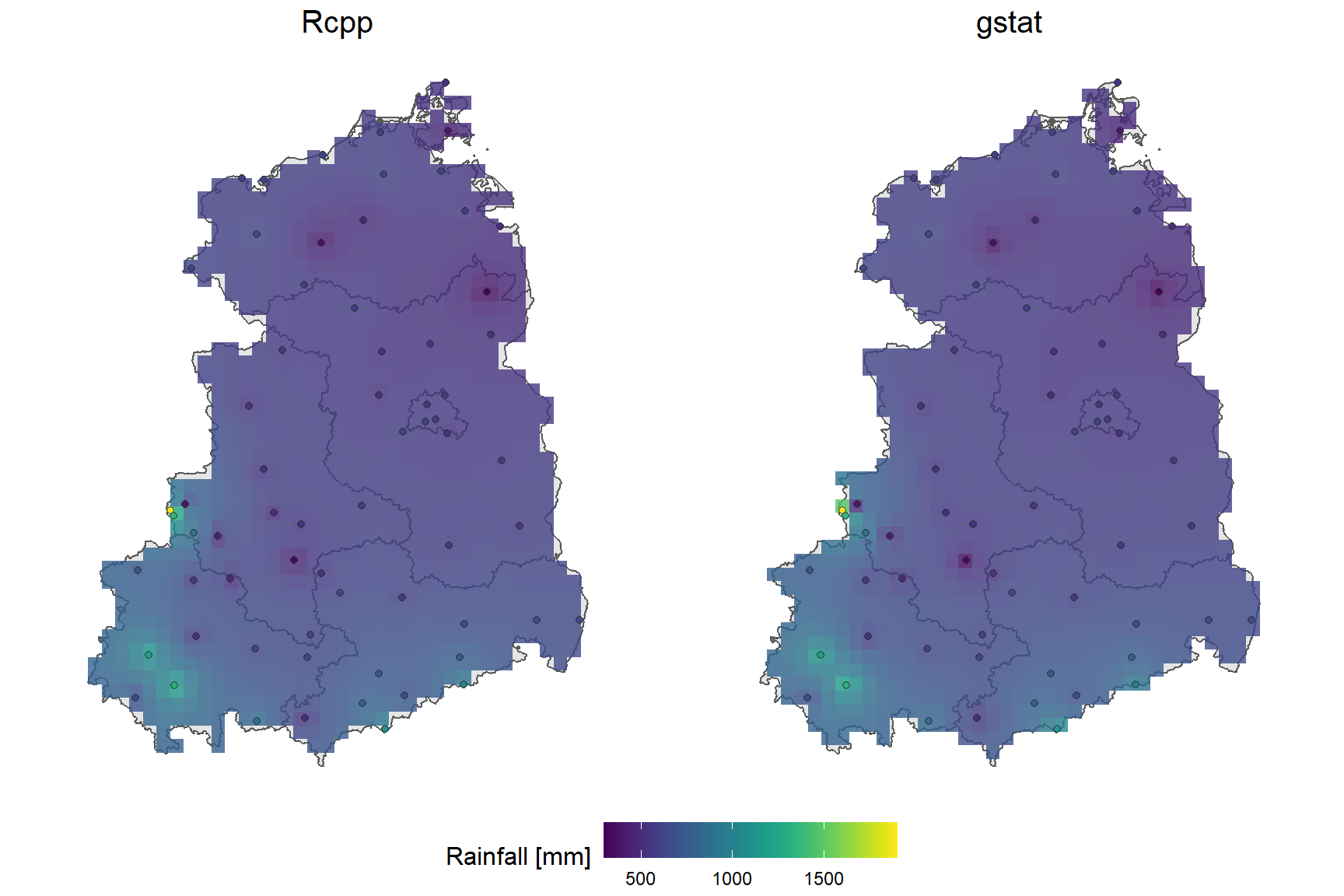
On the first glance, both maps look very similar. Apparently the raster generartion using rasterize results in a small spatial offset compared to the gstat raster. However, the differences are marginal.
Now that we know the algorithm works fine, let’s compare computation time.
load(url("https://userpage.fu-berlin.de/soga/300/30100_data_sets/East_Germany.RData"))
library(microbenchmark)
microbenchmark(
rcpp = dwd_rcpp(aoi = east.germany.states.sp, data = dwd.east.sp,
n = 43, b = 1.5, resolution = 10000),
gstat = dwd_gstat(aoi = east.germany.states.sp, data = dwd.east.sp,
n = 43, b = 1.5, resolution = 10000)
)## Unit: milliseconds
## expr min lq mean median uq max neval cld
## rcpp 215.3333 225.7391 233.3985 229.0763 233.6078 410.7200 100 a
## gstat 223.4818 232.3571 251.1311 237.3653 243.8096 421.1824 100 bAgain, both methods show very similar results. However, when we reduce the resolution (more cells) we clearly see the advantage of using Rcpp.
microbenchmark(
rcpp = dwd_rcpp(aoi = east.germany.states.sp, data = dwd.east.sp,
n = 43, b = 1.5, resolution = 1000),
gstat = dwd_gstat(aoi = east.germany.states.sp, data = dwd.east.sp,
n = 43, b = 1.5, resolution = 1000)
)## Unit: seconds
## expr min lq mean median uq max neval cld
## rcpp 1.888486 1.918858 1.968413 1.962389 1.971613 2.202879 100 a
## gstat 2.358264 2.423042 2.533372 2.516033 2.656117 2.845171 100 bAs mentioned previously, supporting multithreading with Rcpp is simple, too. The dwd_rcpp function supports multithreading, which enables us to compute rainfall interpolation for whole Germany quickly!
aoi <- raster::getData(country = "Germany", level = 1) %>%
st_as_sf() %>%
st_transform(3035) %>%
st_union() %>%
st_as_sf()
dwd.sf <- st_as_sf(dwd, coords = c("LON","LAT"), crs = 4326) %>%
st_transform(3035) %>%
st_intersection(aoi) %>%
rename(Rainfall = rain)Rcpp:
time_start <- Sys.time()
germany_rcpp <- dwd_rcpp(aoi = aoi, data = dwd.sf,
resolution = 500, ncores = 24)
round(difftime(Sys.time(), time_start),1)## Time difference of 3.4 secsgstat:
time_start <- Sys.time()
germany_gstat <- dwd_gstat(aoi = aoi, data = dwd.sf,
resolution = 500)
round(difftime(Sys.time(), time_start),1)## Time difference of 43.1 secsConclusion
In this post I’ve demonstrated how the IDW algorithm can be implemented in C++ using Rcpp. The results match the output of the well established gstat R package. Single core computation time is lower using the Rcpp version, especially for more complex tasks (large number of observations; low raster resolution). But where the Rcpp function really stands out is the capability of multithreading. In my research of Greenspace Visibility I analyse millions of observer locations over a very large area of interest. Using the gstat function would take a long time, but utilizing all of my cores reduces computation time significantly. However, gstat also supports more complex interpolation methods (e.g. kriging).
As a next step I will try to include barriers as demonstrated by GISGeography (2016) to simulate the effect of noise barriers or visible obstacles.
I have included the IDW interpolation algorithm in the GVI R package that also supports LINE and POLYGON features as the observer input:
library(GVI)
germany_rcpp <- sf_to_rast(observer = dwd.sf, v = "Rainfall", aoi = aoi,
beta = 1.5, raster_res = 1000, cores = 22)References
Sebastian T. Brinkmann
BSc Student in Physical Geography
My research interests include spatial analysis, remote sensing, data science, urban forestry and epidemiology.